 XM Knowledge Base
XM Knowledge Base
What are sampling errors and why do they matter?
To understand what sampling errors are, you first need to know a little bit about sampling and what it means in survey research. (If you’re all clued up on sampling already, feel free to skip ahead to the next section.)
When you’re running a survey, you’re usually interested in a much bigger group of people than you can reach. The practical solution is to take a representative sample – a group that stands in for the actual population you want to study.
To make sure that your sample provides a fair representation, you need to follow some survey sampling best practices. Perhaps the most well-known of these is getting your sample size right. (If the sample size is too big, you’re putting in lots of work for no meaningful gain. If the sample size is too small, you can’t be sure your sample is representative of the actual population.)
But there’s more to doing sampling well than just getting the right sample size. For this reason, it is important to understand both sampling errors and non-sampling errors so you can prevent them from causing problems in your research.
Download the eBook: How to Minimise Sampling and Non-Sampling Errors
Non-sampling errors vs. sampling errors: definitions
Somewhat confusingly, the term ‘sampling error’ doesn’t mean mistakes researchers have made when selecting or working with a sample. Problems like choosing the wrong people, letting bias enter the picture, or failing to anticipate that participants will self-select or fail to respond: these are non-sampling errors.
Sampling error definition
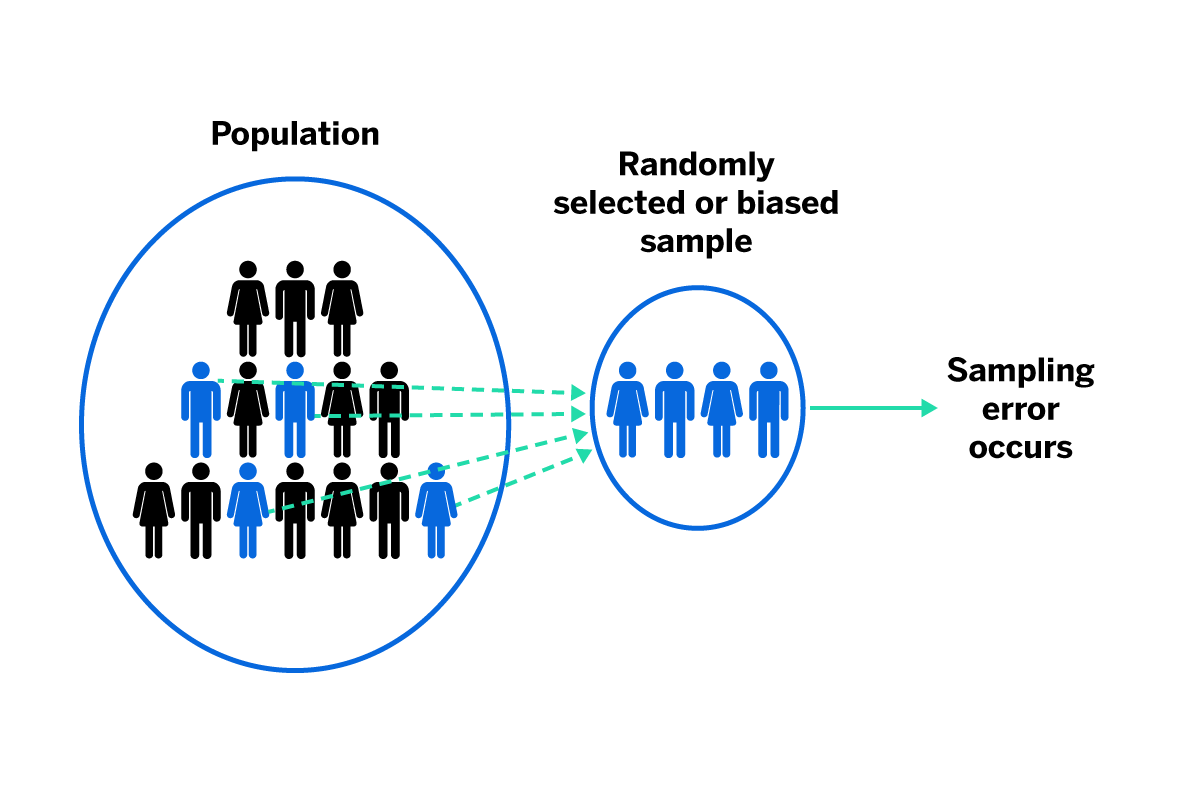
Sampling error, on the other hand, means the difference between the mean values of the sample and the mean values of the entire population, so it only happens when you’re working with representative samples. It’s the inevitable gap between your sample and the true population value.
As OECD explains, the whole population will never be perfectly represented by a sample because the population is larger and more complete. In this sense, sampling error occurs whenever you’re sampling. It’s not a human error, and it can’t be completely avoided.
Interestingly, it’s not usually possible to quantify the degree of sampling error in a study since – by definition – the relevant data for the entire population is not measured.
However, you can reduce sampling errors by following good practices – more on that below.
Is sampling error the same as standard error?
Standard error is a popular way of measuring sampling error. It expresses the extent of the sampling error so that it can be communicated and understood. Sampling error is the concept, standard error is the way it’s measured.
What about standard deviation?
Standard error is a kind of standard deviation. It’s the amount that the sample mean differs from the entire population mean. Or to think of it another way, it’s the amount the sample mean would vary if you repeated the sampling process multiple times.
And confidence intervals?
A confidence interval expresses how much your results are affected by error – i.e. how confident you can be that they are right. Confidence intervals express the upper and lower limits of your margin of error. If the margin of error is narrow, the confidence will be greater. The confidence interval of a result is often expressed in percentages, e.g. 95% or 99%.
Non-sampling error definition
Non-sampling errors can happen even when you’re not sampling. i.e. they need to be avoided whether you’re working with a representative sample (such as with a national survey) or doing total enumeration of your entire population (such as when you’re carrying out employee experience surveys with your workforce).
Non-sampling errors occur when there are problems with the sampling method, or the way the survey is designed or carried out. We’ll cover several of the worst offenders later in the article.

Examples of sampling and non-sampling errors
1. Population specification errors (non-sampling errors)
This error occurs when the researcher does not understand who they should survey. For example, imagine a survey about breakfast cereal consumption in families. Who to survey? It might be the entire family, the person who most often does the grocery shopping, or the children. The shopper might make the purchase decision, but the children influence the cereal choice.
This kind of non-sampling error can be avoided by thoroughly understanding your research question before you begin constructing a questionnaire or selecting respondents.
2. Sample frame error (non-sampling error)
Sample frame error occurs when the wrong subpopulation is used to select a sample so that it significantly fails to represent the entire population. A classic frame error occurred in the 1936 U.S. presidential election between Roosevelt – the Democratic candidate – and Landon of the Republican party. The sample frame was from car registrations and telephone directories. In 1936, many Americans did not own cars or telephones, and those who did were largely Republicans. The results wrongly predicted a Republican victory.
The error here lies in the way a sample has been selected. Bias has been unconsciously introduced because the researchers didn’t anticipate that only certain kinds of people would show up in their list of respondents, and parts of the population of interest have been excluded. A modern equivalent might be using mobile phone numbers, and therefore inadvertently missing out on adults who don’t own a mobile phone, such as older people or those with severe learning disabilities.
Frame errors can also happen when respondents from outside the population of interest are incorrectly included. For example, say a researcher is doing a national study. Their list might be drawn from a geographical map area that accidentally includes a small corner of a foreign territory – and therefore includes respondents who are not relevant to the scope of the study.
3. Selection error (non-sampling error)
Selection error occurs when respondents self-select their participation in the study – only those that are interested respond. It can also be introduced from the researcher’s side as a non-random sampling error. For example, if a researcher puts out a call for responses on social media, they’re going to get responses from people they know, and of those people, only the more helpful or affable individuals will reply. They’re not a random sample of the whole population.
Selection error can be controlled by improving data collection methods and going to extra lengths to get participation. A typical survey process includes initiating pre-survey contact requesting cooperation, actual surveying, and post-survey follow-up. If a response is not received, a second survey request follows, and perhaps interviews using alternate modes such as telephone or person-to-person.
4. Non-response (non-sampling error)
Non-response errors occur when respondents are different from those who do not respond. For example, say you’re doing market research in advance of launching a new product. You might get a disproportionate level of participation from your existing customers, since they know who you are, and miss out on hearing from a broader pool of people who don’t yet buy from you. Like selection error, this leads to a non-random sample that misrepresents the whole population.
Non-response error may occur because either the potential respondent was not contacted or refused to respond. The extent of this non-response error can be checked through follow-up surveys using alternate modes.
5. Sampling errors
As described previously, sampling errors occur because of variation in the number or representativeness of the sample that responds. Sampling errors can be controlled and reduced by (1) careful sample designs, (2) large enough samples (check out our online sample size calculator), and (3) multiple contacts to ensure a representative response.
Be sure to keep an eye out for these sampling and non-sampling errors so you can avoid them in your research.
How can you use sampling and non-sampling errors to improve market research?
Understanding how sampling errors and the different kinds of non-sampling errors work will better equip you to produce reliable results for your business market research.
Data that are skewed by common non-sampling errors, or unnecessary levels of sampling error, can introduce confusion in your business, as different results from different studies might conflict with each other.
Even worse, poor-quality data can lead to false predictions, as in the Roosevelt election when sample frame error led to false confidence in a Republican win. Translate that issue into a business scenario and you could end up badly misjudging your market and making costly mistakes.
How Qualtrics can help
Working with samples and avoiding statistical errors can quickly become a complex task that requires expert knowledge and specialist staff. Fortunately, there are solutions you can incorporate into your business that require neither of those things.
With the Qualtrics market research platform, you can take advantage of market-leading statistical tools that produce reports and data that non-experts can easily understand. With predictions and insights expressed in simple sentences, you can use them to communicate findings at all levels of your company and make crucial business decisions with confidence.
As well as best-in-class software capabilities, you also have access to research services and experts who can support you with everything from survey strategy and creation to panel management and execution.
Find out more about our market research software and capabilities